

As data scientists, we always strive to be accurate in our machine-learning/AI models, i.e., provide better predictions or improved responses to prompts (user queries).
As business-oriented individuals, we always remember that more accurate models require more resources (e.g., money, research, personnel, additional data, compute power).
There is a balance between accuracy 🎯 and cost 💵. This post investigates this accuracy-cost balance.
Why does this question apply to any business whatsoever?
Keep in mind that in today’s world, where AI is widely available (e.g., ChatGPT), this question is relevant to any business, ranging from the smallest one-person business to the largest tech giants you can imagine.
At the time of writing this, there are a variety of AI-based solutions that businesses can utilize. Focusing for a moment specifically on Large Language Models (LLMs), like ChatGPT, you have free solutions like ChatGPT3.5 through a subscription model of the improved ChatGPT4 (which currently costs $20 per month) or even customized models for specific tasks that other companies have built and charge for.
Depending on the task, the business stakeholders need to decide if the improved value provided by improved models is worth the investment. When referring to LLMs, this evaluation is not straightforward since we can’t objectively evaluate the response accuracy.
How would you compare the two poems, written by GPT3.5 and GPT4?
(Prompt: “a short poem about a flower, up to 10 words”)
ChatGPT3.5: “Petals dance, whispering secrets, the flower’s silent poetry unfolds.”
ChatGPT4: “A flower blooms, with grace and beauty. A gift of nature, a joy to see.”
Both nailed it, and the rest is personal taste. Sometimes, the quality is determined by the prompt engineering more than it is by the model.
Businesses that develop their internal models face a more complicated dilemma when determining if a model is accurate enough. Improving models might require more tagging (HR cost), additional integrations to external services (i.e., APIs – Application Programming Interfaces that cost money), and, of course, investments in infrastructure to train the models (compute hours).
Let’s try to see a concrete example.
An illustration with a classification model
I want to illustrate an example that applies to classification models. I.e., models that classify an observation into a category, for example:
- Will this lead mature to a customer and buy my product?
- Will this customer stay loyal or churn?
- Will this patient show up for the doctor’s appointment?
- Is this transaction a fraud or legitimate?
These questions can be answered by classification models, assuming that there is enough data to train and run them. To illustrate the tradeoff, let’s focus on a specific use case (“Will this customer buy my product?”).
Let’s say we’ve developed a model that provides the probability for a product purchase based on the customer’s age, gender, and website session duration. We have developed another improved model that uses the IP address to extract a zip code and a socioeconomic ranking of the customer (and uses it for prediction).
The improved model is more accurate than the original one. Both models are functional; the original is almost “free to run” (only the existing infrastructure’s price), but the improved model has an additional cost of $1 per use.
Let’s also say that if a lead’s conversion probability increases above a certain threshold, the lead will get some kind of swag (i.e., gift) that will result in a definite purchase. Those leads who are not likely to convert will not get the swag (because it won’t help close the deal).
If we are over-sensitive, we will send too much swag, and the cost will outweigh the benefit (over-sensitivity means we are falsely sending swag to those who are not likely to buy). If we are under-sensitive, we will not send enough swag and lose deals we could’ve secured.
Visualizing model performance with an ROC curve
We can analyze this using an ROC curve. It shows the sensitivity of each model on the y-axis (sensitivity = the ability to predict a positive purchase), versus the “1-specificity” of the model on the x-axis. Specificity is the ability to rightly predict that a lead will not convert to a purchase; hence, “1-specificity” (x-axis), is the probability that we wrongly classify a lead as a future customer.
Using the illustration in the figure below, we are setting a goal of 80% sensitivity (which means we are accurately sending swag to 80% of those who will buy after receiving the swag). However, we have an error: in the original model, we will also send swag to 50% of those who are not likely to buy. In the improved model, we have reduced this error to 35%.
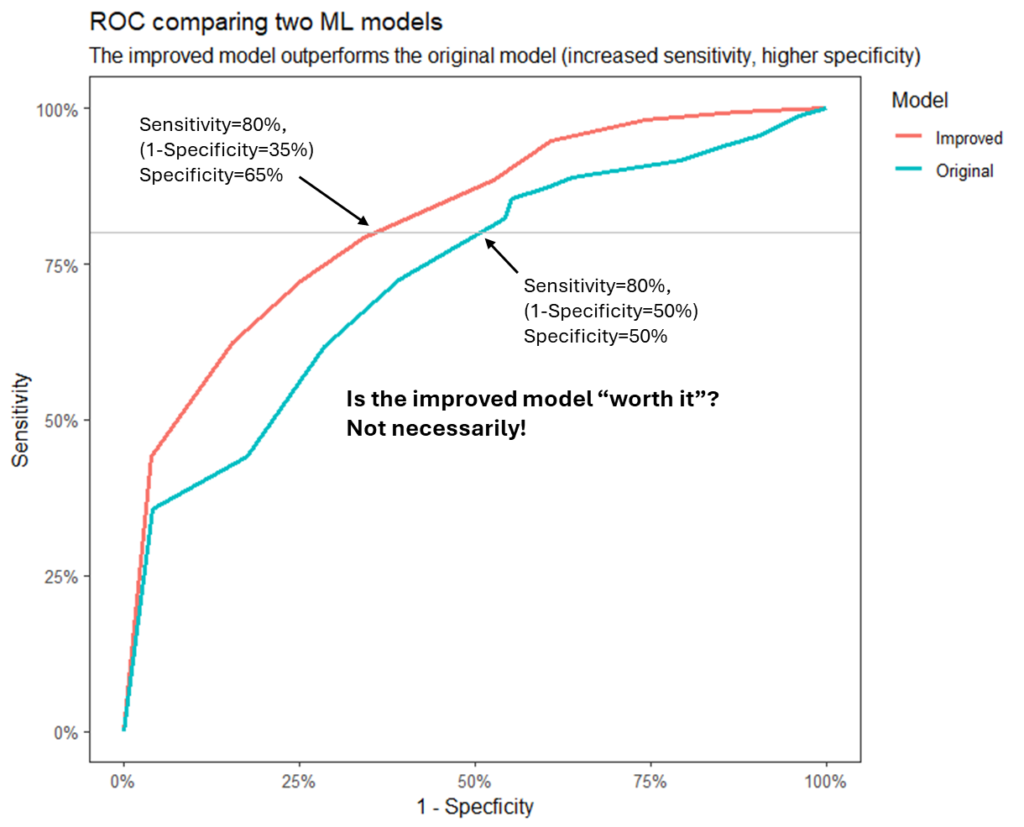
The tradeoff illustrated
Is it worth it? Depending on the numbers (number of leads, swag cost, etc.). Let’s say we have 1000 leads per month and a 10% conversion rate (100 opportunities that will convert if they get the swag). Using the numbers above, we will send swags to 80% of the potential conversions (i.e., 80 leads will convert). In comparison, the original model will yield 450 falsely classified leads (50% out of 900) to get the swag and not purchase. Using the improved model, this number will decrease to 315 (35% of 900).
There is a difference of 135 swag units between the original and the improved model. Note that in the improved model, we are spending 1$ per use, which translates to $1000 per month in our example, more than the original model. The “sweet spot” is $7.41 per swag unit (throwing 135 units * $7.41 per unit = $1000). If a swag unit costs more than $7.41, it is better to apply the improved model (with the cost of $1000); otherwise, stick with the original model.
How to decide?
The tools I outlined above are classical data science tools. If you don’t have a resident data scientist to help you with this, you can contact us 😉. Here are a few pointers to get you started with a simplified cost-benefit analysis version for models. You need to ask the following questions:
- What are the optional models I can use? (what is available on the market?)
- What is the accuracy of each option?
- What is the cost of each model?
- What is the gained value of each model? (higher revenue? less spend?)
- What is the cost of doing nothing? (no model or a truly naive version)
If some of the answers are unavailable, you can either estimate or experiment with the models in a “freemium” model or a limited-time trial/paid version and understand the value they provide. This might give you better intuition about what solution is best for you.
Conclusions
Improving an AI model’s accuracy might be the holy grail for some, but from a business perspective, it is always subject to a cost-benefit analysis. Applying the correct principles, such as examination of sensitivity, specificity, costs, and optimization, might lead to a conclusion that an improvement in the model costs more than what is gained business-wise.
Interested in learning more about model optimization and model cost-benefit analysis? Reach out to our experts today!